
The editorial department of well-known Dutch broadcaster RTL News recently asked for my assistance. Multiple tax files of Dutch citizens had been published via www.docplayer.nl and no one could explain – where did these files come from? Who would have thought that my research would lead to the discovery of one of the world’s most frequently visited websites (!).
TL;DR
Watch the 4 minute RTL News item (in Dutch) on our joint investigation:
Exploring the site
I started looking at the site, which basically contains a lot of PDF files and a search form:
English version of the site: http://docplayer.net/
When navigating through the site, I noticed that it contained a lot of PDF files that shouldn’t be there and the diversity of files is enormous. Almost each file on the site is uploaded by a different user. The users seem to be fake. The site is very simple. You can search and view a file, you can register yourself and upload a file. That’s it. Nothing more, nothing less. You can build such a site in a week.
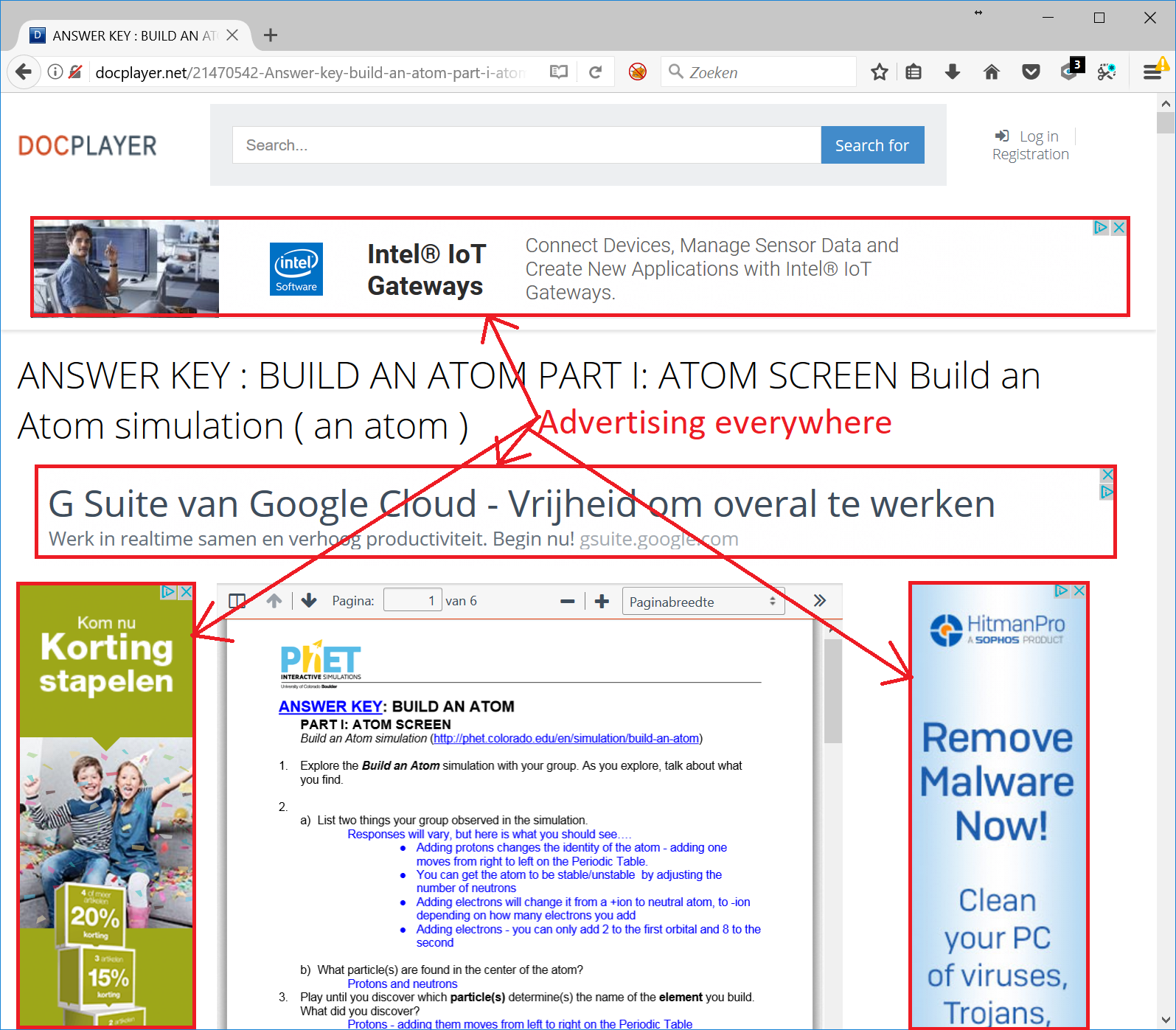
Advertisements everywhere
Each document on the site is accompanied by advertisements:
Registering as a new user
To learn more about the site I registered myself as a new user. I filled in a non-existent mail address, password a, and I was all set! Afterwards a very minimalistic user-interface is displayed:
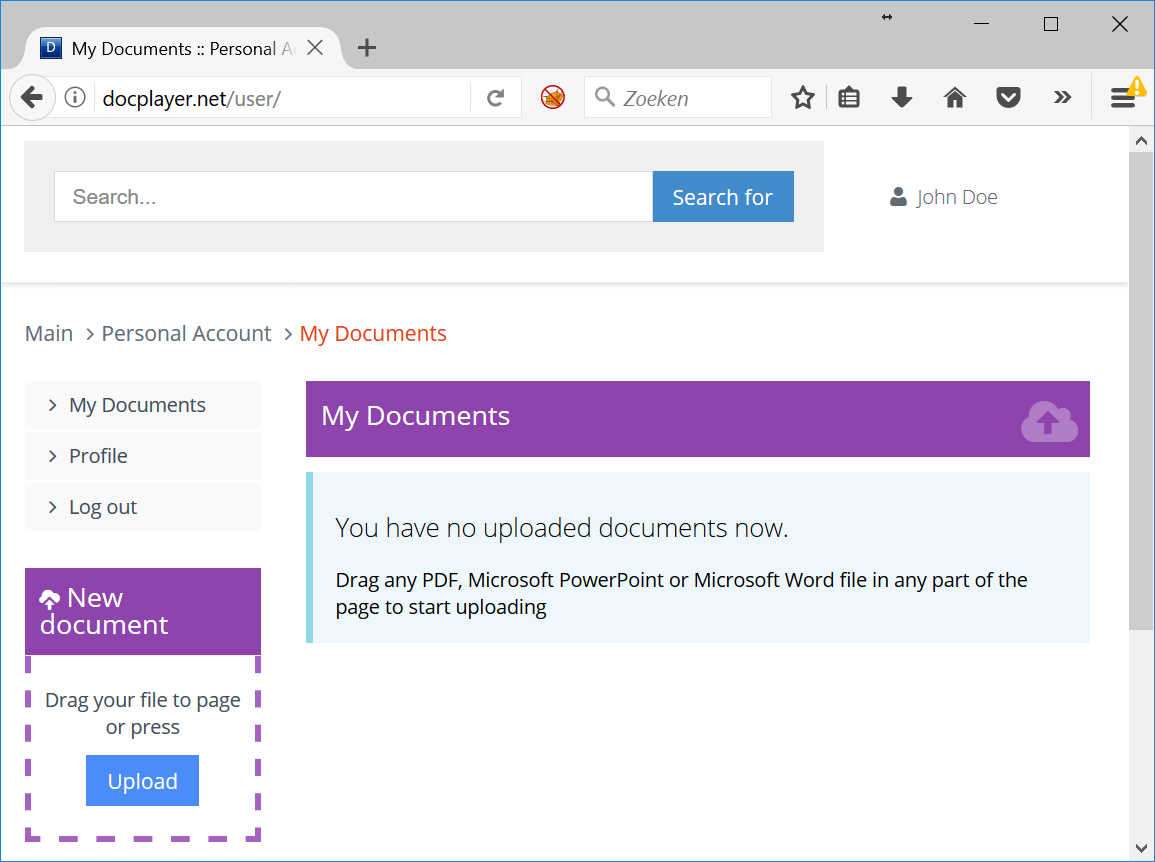
I tried uploading Word, PDF and PowerPoint files in different browsers but couldn’t upload them. The interface and functionality is very basic and partially broken. I get the impression that the owner doesn’t want users to actually use it. It just contains an upload button after you log in, and then you’ll get intentionally demotivated by a malfunctioning upload button.
Documents scraped from other sites
I was wondering how many documents were stored on the site, so I asked Google. It seemed that Google indexed 375.000 web pages. That’s quite a lot! From looking through these documents it was clear that this site was copying (scraping) these documents from other sites.
I even found my own hacking guide that I wrote in 2004 when I was in high school! It has been viewed 290 times in the past 2 years. So that’s 290 visitors that haven’t visited my weblog. This is now getting personal.
Business case
If you host a search engine optimized site with 375.000 PDF files, then you’ll attract a lot of visitors. The average click-through-rate for advertisements on the Google Adwords display network is 0,35%. That means that 3.5 clicks will be generated per 1,000 visitors per advertisement. With 4 advertisements placed on docplayer.nl, it might drive up the click-through percentage towards 1%.
The average price-per-click for advertisers on the Adwords network is between $0.5 and $1. This revenue is split between Google and the website owner that hosted the advertisement.
Total estimated visitors & ad revenue per month
According to Alexa the site is ranked as the 209,334 most visited site in the world, and the 3,945 most popular site in The Netherlands. Not bad! 59% of the visitors seem to be Dutch and 24% Belgium. This is logical because the site contains mostly Dutch content. Unfortunately Alexa doesn’t have intelligence on the amount of visitors for this site.
Another site that estimates traffic data is Informer.com. They estimate that docplayer.nl receives 160,230 unique visitors a month, while ChkWorth.com states they receive 264,753 and SimilarWeb.com states 416,640 visitors a month. It will probably be something in between these numbers.
The estimated advertisement revenue is $988 according to ChkWorth.com. Not a lot.
So who’s behind the site?
Besides a lot of PDF files, the site contains a privacy policy, terms of service and feedback form. The only contact information on the site is found in the terms of service:
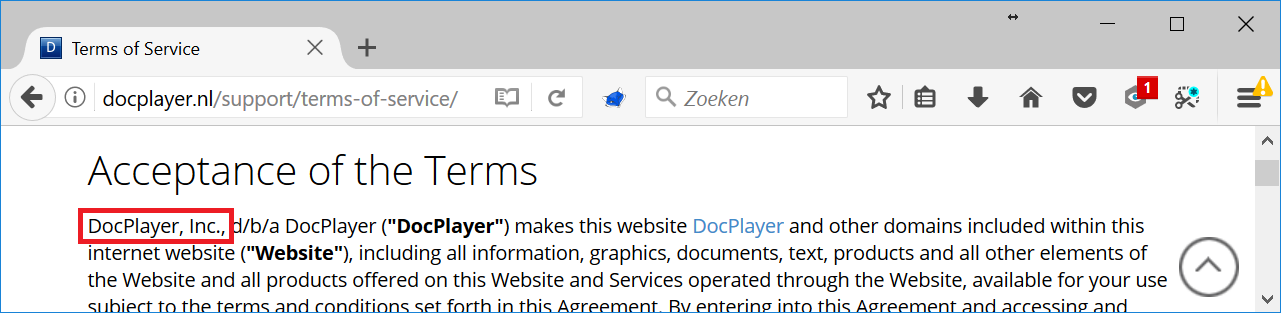
And a bit further:
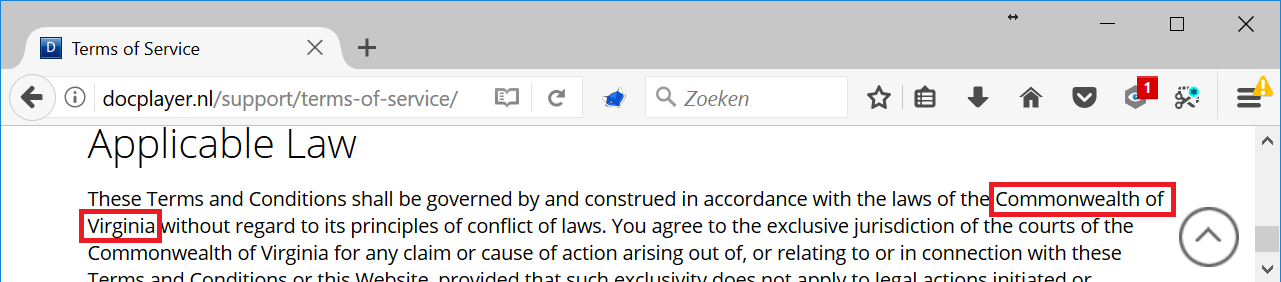
According to the terms of service the website owner is DocPlayer Inc. and based in Virginia. I started googling but couldn’t find a company called DocPlayer Inc. and no one is talking about this company, like it doesn’t exist.
Whois to the rescue!
If your register a domain name, then you have to supply information about who your are and where you live. This information will then be submitted to an open domain name ownership registration database which can be queried. Registration information of docplayer.nl revealed that someone called Vladimir Nesterenko living in Moscow is owner. Doesn’t sound like an American company to me!
The website domaintools.com offers the neat possibility (for paid users) to search for which domain names someone owns. So I searched for all the domain names that belong to Vladimir Nesterenko. Together with some further digging a lot of new domain names appeared related to this platform:
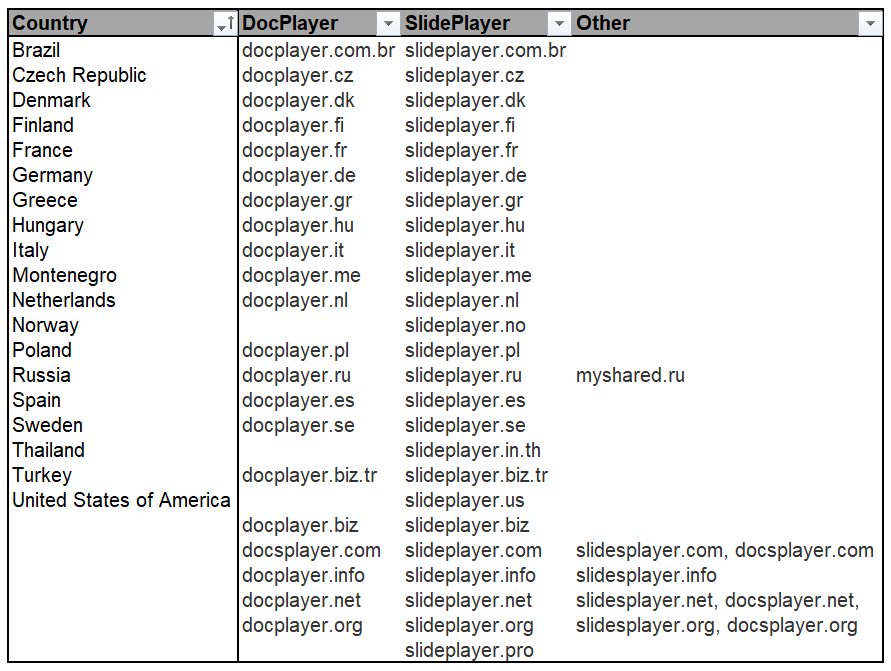 That are quite a lot of domain names! 54 to be precise, in 19 different countries. This enterprise is way bigger than I initially thought!
That are quite a lot of domain names! 54 to be precise, in 19 different countries. This enterprise is way bigger than I initially thought!
DocPlayer & SlidePlayer
I started visiting each site and eventually understood that there were two platforms here. One for displaying PDF files called DocPlayer, and one that displays PowerPoint presentations called SlidePlayer.
Each platform spiders websites in a specific country and looks for PDF and PowerPoint files, copies them, and orders all the files based on the language they’re written in. All the Dutch files will be broadcasted via docplayer.nl, all France content via docplayer.fr, etc. This strategy is excellent for getting these sites to score high in search engines: it’s localized per country, contains a lot of content in the same language and no content is duplicated across these sites.
Obfuscated Google Analytics code
None of the individual sites linked to another. The owner behind the platform took careful steps to mask the international reach of his platform. I even found obfuscated Google Analytics code to hide the analytics IDs and domain names that were in use by Doc-/SlidePlayer:
GET /static/js/28b7/total_blue.js HTTP/1.1
Host: slidesplayer.org
[..]
eval(function(p,a,c,k,e,d){e=function(c){return(c<a?'':e(parseInt(c/a)))+((c=c%a)
>35?String.fromCharCode(c+29):c.toString(36))};if(!''.replace(/^/,String)){while(
c--){d[e(c)]=k[c]||e(c)}k=[function(e){return d[e]}];e=function(){return'\\w+'};c=1}
;while(c--){if(k[c]){p=p.replace(new RegExp('\\b'+e(c)+'\\b','g'),k[c])}}return p}('
U Q=p(){1c(B.X){e\'2.K\':j=\'c-b-3\';d(\'f\',\'c-b-3\',\'2.K\');h;e\'2.J\':j=\'c-b-4
\';d(\'f\',\'c-b-4\',\'2.J\');h;e\'2.M\':j=\'c-b-5\';d(\'f\',\'c-b-5\',\'2.M\');h;e\
'2.I\':j=\'c-b-6\';d(\'f\',\'c-b-6\',\'2.I\');h;e\'2.L\':j=\'c-b-7\';d(\'f\',\'c-b-7
\',\'2.L\');h;e\'2.k.N\':j=\'c-b-8\';d(\'f\',\'c-b-8\',\'2.k.N\');h;e\'2.O\':j=\'c-b
-9\';d(\'f\',\'c-b-9\',\'2.O\');h;e\'2.P\':j=\'c-b-10\';d(\'f\',\'c-b-10\',\'2.P\');
h;e\'2.G\':j=\'c-b-11\';d(\'f\',\'c-b-11\',\'2.G\');h;e\'2.y\':d(\'f\',\'c-b-12\',\'
2.y\');h;e\'2.x\':d(\'f\',\'c-b-13\',\'2.x\');h;e\'2.H.w\':d(\'f\',\'c-b-14\',\'2.H.
w\');h;e\'2.u\':d(\'f\',\'c-b-15\',\'2.u\');h;e\'2.v.z\':d(\'f\',\'c-b-16\',\'2.v.z\
');h;e\'2.A\':d(\'f\',\'c-b-17\',\'2.A\');h;e\'2.F\':d(\'f\',\'c-b-18\',\'2.F\');h;e
\'2.E\':d(\'f\',\'c-b-19\',\'2.E\');h;e\'2.k\':d(\'f\',\'c-b-1a\',\'2.k\');h;e\'2.C\
':d(\'f\',\'c-b-1b\',\'n\');h;e\'2.1e\':d(\'f\',\'c-b-W\',\'n\');h;e\'t.k\':d(\'f\',
\'c-b-S\',\'n\');h;e\'t.R\':d(\'f\',\'c-b-T\',\'n\');h;e\'t.C\':d(\'f\',\'c-b-1v\',\
'n\');h;1u:1t 1s}d(\'1w\',\'1y\');d(\'1p\',\'1i\')};(p(i,s,o,g,r,a,m){i[\'1h\']=r;i[
r]=i[r]||p(){(i[r].q=i[r].q||[]).1f(1j)},i[r].l=1*1n 1m();a=s.1l(o),m=s.1o(o)[0];a.1
g=1;a.1x=g;a.1r=Q;m.1d.1q(a,m)})(1z,B,\'1k\',\'//Z.V-D.k/D.Y\',\'d\');',62,98,'||sli
deplayer|||||||||34773609|UA|ga|case|create||break||analitics_id|com|||auto||functio
n||||slidesplayer|nl|biz|th|se|fi|tr|no|document|org|analytics|gr|dk|hu|in|es|fr|de|
pl|it|br|id|cz|set_ga_counters|net|44|45|var|google|22|domain|js|www|||||||||||20|21
|switch|parentNode|info|push|async|GoogleAnalyticsObject|pageview|arguments|script|c
reateElement|Date|new|getElementsByTagName|send|insertBefore|onload|false|return|def
ault|46|require|src|displayfeatures|window'.split('|'),0,{}));
If you de-obfuscate the JavaScript code above, you’ll see that it contains Google Analytics configuration code, including IDs:
var set_ga_counters = function() {
switch (document.domain) {
case 'slideplayer.de':
analitics_id = 'UA-34773609-3';
ga('create', 'UA-34773609-3', 'slideplayer.de');
break;
case 'slideplayer.fr':
analitics_id = 'UA-34773609-4';
ga('create', 'UA-34773609-4', 'slideplayer.fr');
break;
case 'slideplayer.it':
analitics_id = 'UA-34773609-5';
ga('create', 'UA-34773609-5', 'slideplayer.it');
break;
case 'slideplayer.es':
analitics_id = 'UA-34773609-6';
ga('create', 'UA-34773609-6', 'slideplayer.es');
break;
[..]
case 'slidesplayer.com':
ga('create', 'UA-34773609-44', 'auto');
break;
case 'slidesplayer.net':
ga('create', 'UA-34773609-45', 'auto');
break;
case 'slidesplayer.org':
ga('create', 'UA-34773609-46', 'auto');
break;
default:
return false
}
ga('require', 'displayfeatures');
ga('send', 'pageview')
};
(
function(i, s, o, g, r, a, m) {
i['GoogleAnalyticsObject'] = r;
i[r] = i[r] || function() {
(i[r].q = i[r].q || []).push(arguments)
}, i[r].l = 1 * new Date();
a = s.createElement(o), m = s.getElementsByTagName(o)[0];
a.async = 1;
a.src = g;
a.onload = set_ga_counters;
m.parentNode.insertBefore(a, m)
}
)
(window, document, 'script', '//www.google-analytics.com/analytics.js', 'ga');
I’ve omitted some of the JavaScript above to not make the list too large. The following Analytics IDs per domain could be extracted from the de-obfuscated code:
UA-34773609-3 = slideplayer.de UA-34773609-4 = slideplayer.fr UA-34773609-5 = slideplayer.it UA-34773609-6 = slideplayer.es UA-34773609-7 = slideplayer.pl UA-34773609-8 = slideplayer.com.br UA-34773609-9 = slideplayer.id UA-34773609-10 = slideplayer.cz UA-34773609-12 = slideplayer.fi UA-34773609-13 = slideplayer.se UA-34773609-14 = slideplayer.in.th UA-34773609-15 = slideplayer.nl UA-34773609-16 = slideplayer.biz.tr UA-34773609-17 = slideplayer.no UA-34773609-18 = slideplayer.dk UA-34773609-19 = slideplayer.gr UA-34773609-20 = slideplayer.com UA-34773609-21 = slideplayer.org UA-34773609-22 = slideplayer.info UA-34773609-44 = slidesplayer.com UA-34773609-45 = slidesplayer.net UA-34773609-46 = slidesplayer.org
I checked if I could fill in the missing IDs in above list by performing a reverse look-up on other sites belonging to Google Analytics account UA-34773609, but unfortunately I couldn’t find anything useful.
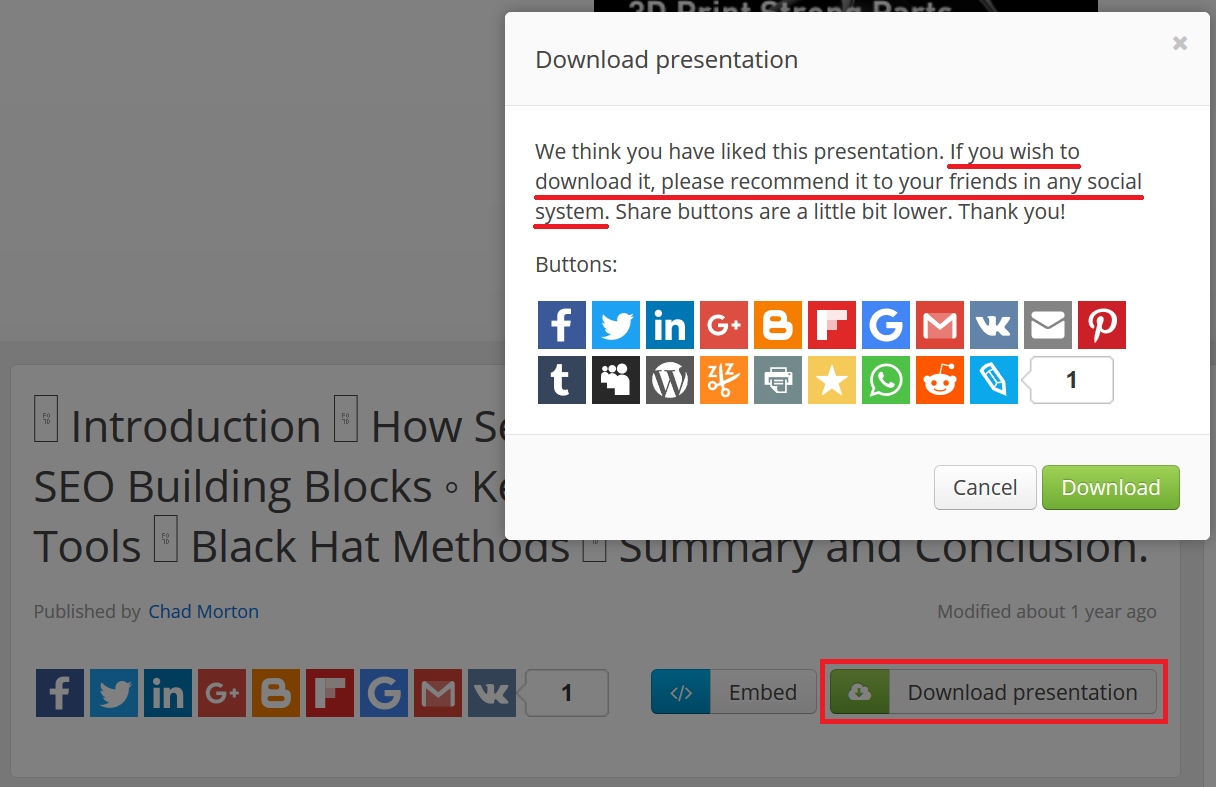
Oh, so you want to download a presentation? Hold on!
I explored the SlidePlayer website further. What made me laugh is that if you want to download a PowerPoint file, you first have to click on a share button:
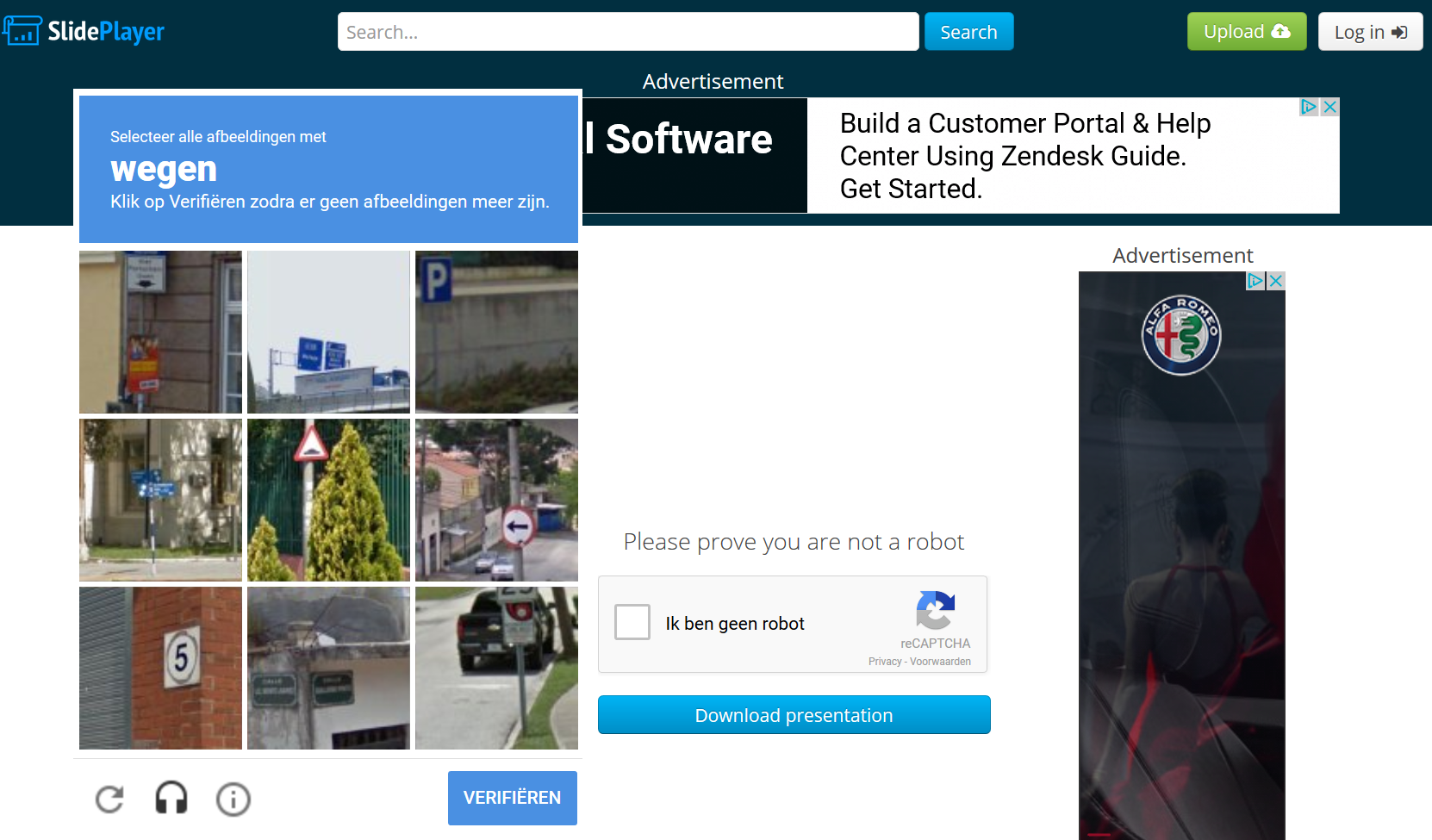
Next, the ‘download’ button becomes active. When you click it, you have to solve a puzzle:
And to finish you need to wait for 60 seconds:
If you’ve made it through the whole process, you’re rewarded with a downloadable PowerPoint file. Now that’s a hell of a customer journey!
Of course these hurdles are there to make you go away. They purposefully create a bad customer experience so you don’t pay attention to the site.
The ideal visitor according to DocPlayer
From the website perspective, the ideal visitor comes from Google and lands on a webpage that hosts a PDF or PowerPoint file. Hopefully the visitor clicks on an advertisement surrounding it and leaves the site. The worst case scenario is that the visitor stays on the site and creates an account and starts using the platform. This will generate attention to the site. Visitors might become aware with what’s going on, and that’s the last thing the owner wants. His platform is full of PDF files that are copied from other sites and re-hosted. This is illegal and if someone creates fuzz about this, it could be the end of his business.
Reported sensitive documents are taken down
Doc- and SlidePlayer have a complaint form attached to each document. If the spider copied documents from other sites that shouldn’t be on the internet in the first place, the owner of those documents won’t be happy if these documents are re-hosted on the internet by Doc-/SlidePlayer, made searchable by Google and archived by the Internet Archive.
RTL News found out that the staff behind Doc- and SlidePlayer respond quickly to requests to take down sensitive content from the sites. They seem to have absolutely no interest in hosting sensitive files, as this draws negative attention to them that could blow the whole cover of their operation.
And that just happened, because RTL News got a complaint from someone that sensitive tax files were hosted on the site, they decided to ask me to join the team to get to the bottom of this.
An empire arises
So how many visitors a month and thus how much money are these two platforms generating exactly?
To get a somehow reliable estimation of the impact of this operation, I started noting down statistics in a spreadsheet that I copied from other sites such as Google, Alexa, Informer, ChkWorth and SimilarWeb that analyze and track the popularity of websites:
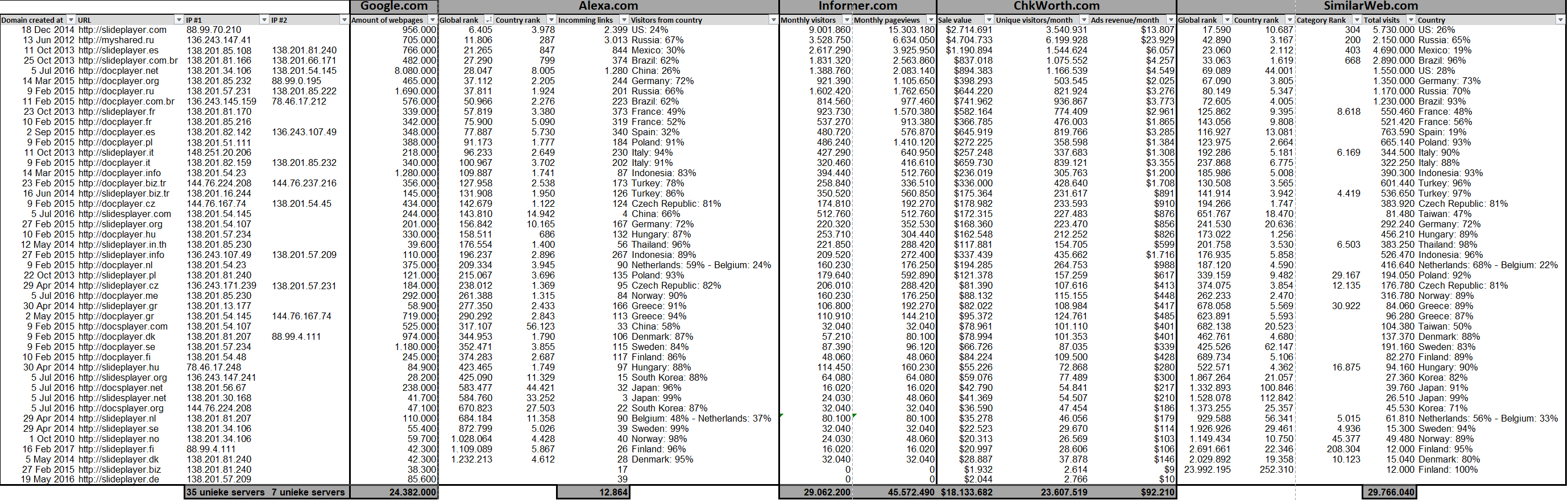
Statistics about the Doc-/SlidePlayer empire. Click on the image to enlarge it.
Very interesting statistics arise
- 45 domain names are in active use in 19 different countries.
- 42 dedicated servers in Germany run the whole operation.
- 24,3 million PDF and PowerPoint files are hosted on all sites combined.
- These sites have at least 12.843 incoming links.
- 23 to 29 million unique monthly visitors for all the sites combined.
- Estimated 100 million page views per month.
- The sites generate a roughly estimated add revenue of $92,210 each month.
- slideplayer.com is ranked as the 6,047 and myshared.ru is ranked as 11,806 most visited site in the world. 11 other sites are also ranked in the top 100,000 list.
Looking at the amount of dedicated servers that support the infrastructure, and the fact that multiple sources all roughly report the same statistics, it’s safe to say that some serious money is being made with this simple but very scalable and effective infrastructure.
Meet Vladimir Nesterenko
When looking at the ownership information of all the domain names, on name keeps popping up:
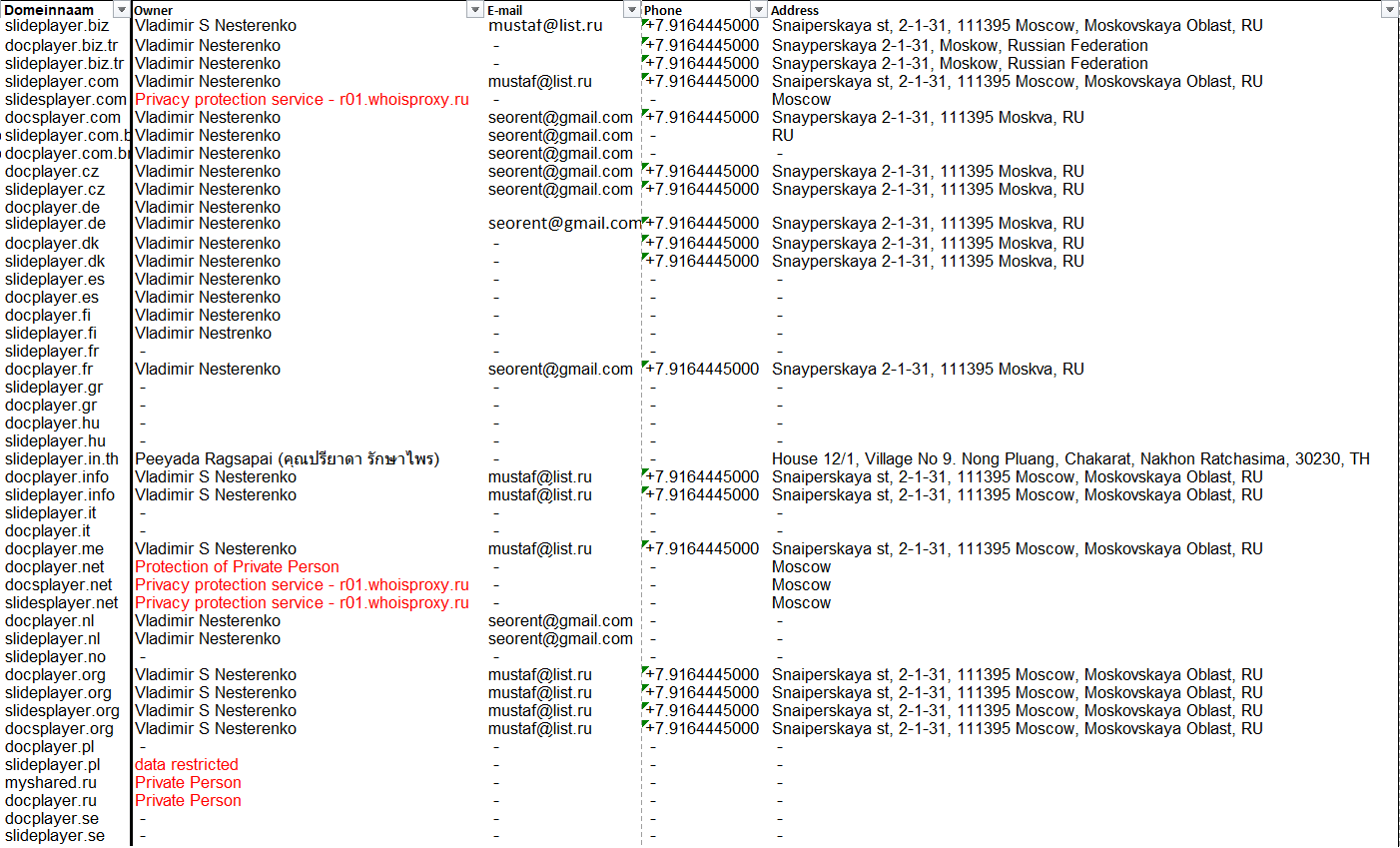
Some whois information is anonymized, but most isn’t. The same phone number and address in Moscow is listed on all domains where these properties are visible. According to another source, a public address book at locatefamily.com, someone under the name Vladimir S. Nesterenko is living at Snayperskaya st, 2-1-31 in Moscow. Vladimir lives according to Google Streetview it’s an apartment complex far away from the Moscow city center:

A correspondent from RTL News paid him a visit in Moscow, but he wasn’t home. People around there confirmed he lived there.
Back to the terms of agreement and privacy policy
The privacy policy and terms of agreement on Doc-/SlidePlayer is extensive and looks professional. I bet they copied that one also! I copied a few lines from the privacy policy and terms of agreement and found out that they copied those from slideboom.com. They also copied their logo and slightly modified it:
 The resemblance between the SlideBoom and Doc-/SlidePlayer logos is remarkable:
The resemblance between the SlideBoom and Doc-/SlidePlayer logos is remarkable:

I bet our Vladimir got the idea of creating a website that hosts PowerPoint files from visiting SlideBoom.com. But instead of waiting for a long time for users to upload content, Vladimir took the shortcut and just copied all the PowerPoints he could find on the internet.
Has He Been Pwned?
The whois information contained two e-mail addresses [email protected] and [email protected]. I searched for hits on these addresses in known data breaches on haveibeenpwned.com.
[email protected] is hit in the Exploit.In and VK data breach, and [email protected] is also hit in the Exploit.In, Onliner Spambot and more interestingly: the Bitcoin Forum and BTC leak. The Bitcoin exchange BTC-E was hacked in 2014 and 568k accounts were exposed. The data included email and IP addresses, wallet balances and hashed passwords.
If you earn $92,210 each month by hosting illegally 24.3 million PDF files, that’s a hard story to sell to the tax authorities. Bitcoin is a way stealthier way of storing wealth, and our Vladimir seems to be well aware of that.
Google: partners in crime
Google is partners in crime with Vladimir. They bring him all the visitors and split the cut in advertisement revenue. Google also profits when people click on their advertisements. They’ve made millions in the last few years hosting their ads on Doc-/SlidePlayer.
RTL News contacted Google spokespersons but they didn’t want to look into this matter and seems to be fine with the current situation. If nobody complains further, they earn half a million dollar a year, so why take these reports serious? Media is not law enforcement.
As RTL couldn’t get through, I also tried contacting Google. Their spokesperson doesn’t want to comment on the matter. It seems Google is fine with the situation. Why bother? It’s very profitable!
Rounding up
What started with a few tax files that were hosted on docplayer.nl, let to the discovery of an empire that makes a million dollar a year by illegally hosting 24.3 million files copied from other sites. This cover/fake site is an elephant in the room that nobody is aware off.
I think it’s wrong what these guys are doing. They’re basically stealing 30 million visitors a month from sites that authored the original content, which results in at least 1 million dollar combined that is stolen per year from all those websites that got copied.
Now the mystery behind the site is solved, I reported back to RTL. Today they presented our research on Dutch national TV and their website:
Update October 9, 2017: Dutch political party D66 asked Dutch minister to take action
Questions from member Verhoeven (D66) to the Minister of the Interior and Kingdom Relations about the news item ‘Russian whizkid gets rich from your documents’:
1: Bent u bekend met het bericht ‘Russische whizzkid wordt rijk door jouw documentjes’?
2: Klopt het dat de eigenaar de bestanden op een illegale manier heeft verkregen?
3: Welke acties bent u voornemens te nemen tegen deze website?
4: Bent u bereid om met Google in overleg te gaan om actie te ondernemen tegen deze website?
5: Bent u zich ervan bewust dat in sommige Kamerstukken gelinkt wordt naar de betreffende website? Bent u bereid ervoor te zorgen dat dit in de toekomst niet meer gebeurt?
Update October 11, 2017: Another Dutch political party asks minister questions
Questions from member Bruins Slot (CDA) to the Minister of the Interior and Kingdom Relations about the news item ‘Russian whizkid gets rich from your documents’
1: Heeft u het item van RTL nieuws over docplayer.nl gezien?
2: Hoe kan het dat op deze site verschillende belastingaangiftes met burgerservicenummer staan? In hoeverre mag iemand andermans persoonlijke informatie op zijn eigen site zetten?
3: Hoe komt Nederlandse content op een klaarblijkelijk door een Rus beheerde site terecht?
4: Welk gevaar bestaat er dat de beschikbare documenten met burgerservicenummer en namen tot identiteitsfraude leiden?
5: Welke risico’s zijn er dat via deze site snel virussen kunnen worden verspreid? Hoe wenselijk is het dat de overheid deze site ook gebruikt bij het maken van verwijzingen in Kamerstukken (bijvoorbeeld Kamerstuk 34595, nr. 33, p. 5)?
6: Welke mogelijkheden zijn er vanuit de overheid om ongewenste content, zoals ingevulde belastingaangiftes met burgerservicenummer of het personeelsblad van de inlichtingentak van de Militaire Inlichtingen- en Veiligheidsdienst, van de site te halen?
7: Welke mogelijkheden zijn er voor individuen, zo mogelijk gesteund door de overheid, om ongewenste content, zoals ingevulde belastingaangiftes met burgerservicenummer, van de site te halen?
8: Welke verantwoordelijkheid kan hier van Google verwacht worden? Heeft de Nederlandse overheid mogelijkheden om Google tot actie over te laten gaan? Zo nee, waarom niet?
Update November 8, 2017: Belgium political party Open VLD asked questions to the Belgium Secretary of State
Belgium politician Martine Taelman from party Open VLD asked questions to the Belgium Secretary of State:
The DocPlayer website gathers hundreds of e-books, periodicals, song texts, but also completed tax returns and CVs including data on salary and wealth. According to the Dutch Ministry of the Interior, this data can be used to commit identity fraud. The materials on this site appear to have been made available by users, but this is not the case. In reality, these pdf files were collected by an intelligent computer program. The documents have been placed on the site in a completely automatic way, by means of a robot, a kind of small “vacuum cleaner” that constantly scours the entire internet in search of documents and that places them on the DocPlayer site. As long as it is a question of public documents, there are no direct legal objections, but there are any objections when this data comes from poorly secured internet connections or data leaks. Private documents that accidentally end up on the Internet – for example as a result of a data leak – are also placed on this site.
According to the Nederlandse National Cyber Security Centrum, the police and the Authority persoonsgegevens (Authority for the Protection of Personal Data), what this site does is illegal because it violates privacy and copyright law on a large scale.
The income of this illegal Russian site depends on the number of clicks on certain articles – via search engines such as Google – and on the copy – sometimes futive – of documents from thousands of Internet users who do not suspect anything. Currently, this site already operates in about twenty countries.
The authority is limited in its action because the sites are located abroad. On the other hand, Google can intervene. In the Netherlands, the D66 party, among others, is calling for Google to be questioned on this issue.
As for the cross-cutting nature of the issue: the various Governments and links in the security chain have agreed on the phenomena that must be addressed as a matter of priority over the next four years. These are defined in the Comprehensive Security Framework Note and the National Security Plan for the period 2016-2019 and were discussed at an Inter-Ministerial Conference in which police and justice actors also participated. Computer crime and the protection of privacy are among the priorities set. It is therefore a cross-cutting regional competence in which the regions are mainly involved in the preventive aspect.
My questions in this regard are as follows:
1) What do you think of these kinds of clickbait sites that automatically collect data from citizens and companies, including private documents that have been obtained as a result of a data leak or a bad internet connection, ignoring copyright and violating, sometimes very seriously, the right to privacy? Have you ever received any complaints in this regard? If so, which sites were incriminated? Is it true that they generally operate from Russia?
2) Have you already made representations on this subject to the Commission for the Protection of Privacy or through bilateral contacts in order to check to what extent these sites infringe on the privacy of our citizens and our businesses? Can you give details of your answer?
3) Are you willing to engage in a dialogue with search engines like Google and can you give details about the timing and content of your efforts?
The Belgium Secretary of State responded on these questions on December 6, 2017:
1) According to the new European General Data Protection Regulation, which will enter into force in May 2018, a controller established outside the European Union is subject to the Regulation “when the processing activities are related to the monitoring of the behaviour of individuals, insofar as it is conduct that takes place in the Union”.
If, as your question says, Doc Player automatically places on its site data of European citizens collected by robots, it must be considered that this site is subject to the regulation and that therefore the persons concerned have the right to be informed of the collection of data, to have a copy of it, and to oppose this processing.
Regarding the complaints, I asked the Privacy Commission and they replied that they had not yet received a complaint related to Doc Player.
(2) The Commission for the Protection of Privacy has drawn attention to the fact that since they are Russian sites or servers, it has no way of accessing them. When the problem goes beyond the Belgian framework, it will be dealt with at European level, within group 29, in order to determine whether a European approach is possible.
3) Before taking action, it is appropriate to await the conclusion of the investigation launched by the Commission for the Protection of Privacy with Group 29 and to determine what measures and sanctions they will have to take.
Update November 9, 2017: Dutch minister seems to be fine with the situation
The Dutch minister of Safety and Justice (Grapperhaus) answered (pdf) the written questions from Dutch politician Verhoeven (D66). Grapperhaus finds it unnecessary to ask Google to block the site:
[..] As stated earlier, the government is committed to a free and open internet. Blocking content on internet via Google is therefore not preferable. [..]
The full answer from the minister (Google translated):
Answers from the Minister of Justice and Security to the questions of Member Verhoeven (D66) about the message ‘Russian whiz kid gets rich because of your documents’. (submitted October 9, 2017, no. 2017Z13449)
Question 1: Are you familiar with the message ‘Russian whiz kid gets rich because of your documents’?
Yes.Question 2: Is it true that the owner obtained the files illegally?
It is a bad thing that such documents, including personal data, are online. However, it cannot be stated in advance that this data has been obtained illegally. It appears that these data, which may also include personal data, have been placed on the internet consciously or unconsciously by users and have subsequently been collected by this site.Question 3: What actions do you intend to take against this website?
The government values a free and open internet. Where there are violations of the Personal Data Protection Act (Wbp), the Dutch Data Protection Authority is the independent supervisory authority, which has the power to act in the event of violations of the Wbp and determines when to do so. In addition, pursuant to Article 4 of the Wbp, this Act only applies to the processing of personal data in the context of activities of an establishment of a controller in the Netherlands, as well as in the case of processing of personal data by or for the benefit of a controller. that does not have an establishment in the European Union, using means, whether automated or not, that are located in the Netherlands, unless these means are only used for the transfer of personal data. The Wbp therefore does not apply if it concerns processing operations by a controller who does not have an establishment in the Netherlands, using means that are not located in the Netherlands.Question 4: Are you willing to consult with Google to take action against this website?
As stated earlier, the government values a free and open internet. Making data on the internet inaccessible via Google is therefore not preferable. This is all the more true because data, including personal data, is therefore still available on the internet.Finally, citizens whose personal data has been wrongly published on this website can submit an individual request for removal to the search engines if they need it, in order to remove the results after a search on their name. In any case, this makes their data less easy to find.
Question 5: Are you aware that some parliamentary documents link to the relevant website? Are you prepared to ensure that this does not happen again in the future?
Yes, I have indeed noticed in response to the reports that reference is made to this website in various publications from or through the government. As far as I am concerned, it is preferable to refer to the primary source and for this purpose the channels of the national government (such as www.rijksoverheid.nl and www.officielebekendmakingen.nl) are primarily preferred in the light of trusted communication with citizens. This subject will be brought to the attention of the appropriate bodies of the national government.
Update November 10, 2017: Tweaker.net: “Minister: no action against Russian scraping site with 4.3 million files”
Dutch tech news site Tweakers.net writes the following (Google translated):
“Minister Grapperhaus of Justice and Security has informed the House of Representatives in a letter that the government will not take any steps against the scraping website of a Russian, which is said to contain 4.3 million files, including files with personal data.
In response to the question of D66 MP Verhoeven whether the minister intends to take action against the website, Grapperhaus says that the cabinet values a free and open internet. Based on this view, the minister says that it is not preferable to make the data on the website inaccessible via Google. He finds this undesirable, among other things, because the data has not yet disappeared from the internet.
Grapperhaus also mentions the possibility for individuals to submit a removal request to search engines, in order to have the search results removed with any personal data. In his answer, the minister does not mention any actions that his ministry will take against the website.
The minister calls it a ‘bad thing’ that the documents of persons, including personal data, are online on the scraping website, but he states that it cannot be established in advance that the data was obtained illegally. According to the minister, it seems that the files were placed on the internet by users consciously or unconsciously.
The minister also refers to the possibility of the supervisory authority, the Dutch Data Protection Authority, to act in the event of violations of the Personal Data Protection Act. Grapperhaus immediately indicates that the law probably does not make it possible for the supervisor to intervene, because the rules only provide scope for the AP to act if the controller is established in the Netherlands and makes use of the resources that are located in the Netherlands. located.
The regulator previously stated that what the site does is simply not allowed. Not only would privacy be violated, but copyright would also be compromised because the files would be added to the site’s collection without permission.
It concerns the website docplayer, and to a lesser extent its sister site sideplayer. These websites collect the data by scraping other website. According to researcher Sijmen Ruwhof, who previously devoted a blog post to his findings about the website, the websites do have a properly working takedown procedure with which certain files can be removed. Ruwhof writes that the entire network of sites extends over 45 domains in 19 different countries. Hosting would take place in Germany on 42 servers.
According to an estimate of the site’s size and revenue, the websites could earn its Russian owner $1 million a year. The site would mainly contain PDF and Office documents.”
Update November 10, 2017: Dutch news site nu.nl
Dutch news site nu.nl writes (Google translated):
“No action will be taken against the Russian website DocPlayer, which automatically publishes PDF files from internet users.
This is stated by Minister Ferd Grapperhaus of Justice and Security in an answer to parliamentary questions asked about the website (pdf).
The site, which is owned by a Russian, is said to contain 4.3 million files that are collected and published by a computer program. Since this is done automatically, private documents also appear on the website. This concerns, for example, completed tax returns and government documents that have been mistakenly put online by internet users.
Grapperhaus calls the fact that these kinds of documents are on the site “a bad thing”. But according to the minister, it is not clear whether the files were obtained illegally.
Grapperhaus also refers to the Dutch Data Protection Authority, which has the authority to act in the event of violations of the Personal Data Protection Act (Wbp). However, the supervisor can only intervene if the controller is established in the Netherlands.
Search results
Minister Grapperhaus writes that the cabinet “values a free and open internet”. Therefore, it would not be preferable to have the information made inaccessible via Google. Also because this does not completely remove the data from the internet.The minister states that people whose personal data is incorrectly on the website can submit a removal request to search engines. This does not make the data disappear, but it becomes less easy to find.”
Update November 14, 2017: Dutch lawyer Ellen Timmer responds
Dutch lawyer Ellen Timmer reflects on her weblog on the ministers answers (Google translated):
“[..] The answer shows that the Dutch government thinks that making money by means of an internet search engine such as docplayer is an innocent and harmless activity, to which normal privacy rules apply. […]
This means that scraping is legal, even on cloud locations that are open due to security flaws, as TweakersNet has found, among others. The article points out that there is not only a privacy side to it. Also, soliciting and putting on one’s own site copyrighted documents is in violation of intellectual property law. [..]” read more >>
Update November 15, 2017: Dutch lawyer Arnoud Engelfriet responds
Dutch lawyer Arnoud Engelfriet on his weblog on the ministers response (Google translated):
“[..] as a minister there is of course really little you can do about this, after all, that task lies with supervisors such as the Dutch Data Protection Authority or with the people affected by this publication. No matter how annoying, it is a civil matter – you have to file a lawsuit if your copyrights are violated or your privacy is compromised.
[..] The argument that that data was “consciously or unknowingly placed on the Internet by users and then collected by this site” is of course completely irrelevant and it is a shame that it is so prominent in the front of the answers. Because that doesn’t matter; even if you consciously place something on your site, it may not be copied in such a handy boys’ site.” read more >>
Update May 5, 2018: Civis Mundi writes: ‘Google does nothing against criminal scraping company DocPlayer’
The following article is Google translated:
“A year ago, [Dutch, red.] Member of Parliament Kees Verhoeven (D66) said that a rogue Russian site earns wealth by secretly copying documents of thousands of unsuspecting Europeans. As with many, the politician drew his outrage from a news report by RTL Nieuws and blogger Sijmen Ruwhof.
Ruwhof and RTL Nieuws investigated the site Docplayer No less than 4.3 million documents were then illegally offered. The Russians behind that site scrape other websites ranging from Academia.edu, Researchgate to personal websites and government sites. According to the government (Dutch Data Protection Authority) Docplayer violated privacy. Not to mention copyright infringements. Other illegal sites like Slides.tips do the same.
The National Cyber Security Centre (NCSC) also expressed this view in 2017. “Not only would privacy be violated, but copyright would also be compromised because the files would be added to the site’s collection without permission.” Sijmen Ruwhof illustrated the approach on his blog. Ruwhof estimated the revenue. The Russian owner can count on roughly a sloppy one million dollars a year. The crawled PDFs and Office documents must have hit the site in a very bizarre way because the upload function turns out to be fake.
The entire network of rogue sites includes 45 domains in 19 different countries. The hosting is in Germany. The National Cyber security Centre, the police and the Personal Data Authority said in 2017 that what the site is doing was ‘illegal’, but six months later nothing has been done about it.
Verhoeven felt at the time that Google should take its responsibility. “The government can do little, because the sites are located abroad. Google can. I’m going to ask the cabinet to address Google on its responsibility.” A strange twist by an MP to portray the government as powerless at a time when the Spanish government can have an arrest warrant executed in Germany.
Some time before Ruwhof’s publication in question, the undersigned had also looked up the whois data of the domain holder and contacted both Google and dns.be (the register of Belgian domain names). DNS didn’t want to do anything. But apparently the site has been registered to another since December 2017.
If you contact that rogue Vladimir Nesterenko to demand that you delete your documents, they will send the same email every time. Which also has different formats per paragraph. No signing, and it’s full of nonsense. DMCA is U.S. regulation and not international. The explanation is certainly in bad faith. As if they don’t know where they scrape and can’t search by name in their own database.
That crook is guarding himself to put names in his e-mails. Always claims that the complainant has to give the url because he supposedly finds nothing and tries to stop things instead of explaining how those documents got on his site when no one can upload as Ruwhof demonstrated. It’s him to do SEO: search engine optimisation. Techniques to lure people to sites via Google.
Bizarrely, Google does nothing because if an SME uses a photo that appears to have been stolen from another site, they immediately turn down the position in the search results a few clippings. The real reason, of course, is that Docplayer makes good money from Google Ads and, of course, Google makes the most from those ads. For example, Google has a perverse interest and is therefore complicit. Any sucker who surfs through Google to a stolen PDF or presentation will earn Google money per view- while if Google sends that same surfer to the site of a government agency, university or publisher, it won’t give them a dime of money.
The real reason amazon also does nothing against rogue people who sell digitally printed books with old Google-scanned publications from university libraries, titles that are often owned by scientific associations. Even more so from those looters registering eeb ISBN number, Google retrieves the publications of Google Books and only displays extracts. For example, the looters accaparize the copyright of third parties, again with complicity from Google. Amazon and its former subsidiaries hide behind the excuse that the authors would have died aged 70. It is strange why those same people do not dare to sell old prints of the Royal Society in London via Amazon. eBay also sells those digital heist prints, and while it prides itself on a battle against counterfeits and copies, eBay doesn’t take them off the site either after complaints through the calibrated notification. In essence, Google, eBay and Amazon think they have nothing to fear thanks to international legislation that doesn’t work and a legal system in the United States that lets them plunder with impunity because in Europe no government has the decisiveness, the manpower and the courage to deal with them for every crime.
Making a complaint against Docplayer in Belgium is even laughable. Where the Dutch counterpart speaks of invasions of privacy, the Belgian counterpart considers that it does not work out anyway. The Belgian Privacy Commission reacted laconicly.
The fact that the Dutch or Belgian authorities do nothing against gross violations of privacy, copyright or even good decency seems to strengthen them in that reasoning. That after the fifteen minutes of celebrity Verhoeven did not let us hear about his tirade in the House of Representatives. The fact that the prosecution did nothing and that looters like Nesterenko can continue to do so with impunity and google even proves helpful in doing so says a lot about the culture of flame politics based on news items that if the broadcast is forgotten turns out to be dead letter.
On the eve of GDPR, the government would first prove better that it enforces the existing much weaker legislation than that it makes all kinds of consultants big money from a European regulation that no longer even has to be transposed into national legislation by the national parliaments.”
Update December 10, 2020: ‘Transfer domain docplayer.dk or close it’
A Danish organization for the defense of copyright had urged the relevant authority to transfer the domain docplayer.dk to them or to close it. The authority declined the demand, since the name of the domain was not wrongly held. Concerning the illegal content of the site, the organization should go to court. In its complaint it demonstrated, among others, that alleged names of uploaders where taken from lists of deceased persons published on the internet. This site does not publish the material submitted by the plaintiff, running to more than 100 pages)
“DECISION docplayer.dk
RettighedsAlliancen
courage
Vladimir Nesterenko
10. december 2020.
Claims:
The complainant’s claim Principal: The respondent is ordered to transfer the registration of the domain name “docplayer.dk” to the complainant. Alternatively, the registration of the domain name “docplayer.dk” is deleted. The defendant’s claim The respondent has not responded to the case.
Sagsfremstilling:
The complaint states: “The Rights Alliance is an interest group fighting to protect the rights and conditions of creative industries on the Internet. We do this, among other things, by reporting violations of our members’ rights to the police, and by conducting civil proceedings for our members as mandatar. Our association consists of large and small companies, producers, associations and organisations within the creative industries. Docplayer.dk is a service where Danish-language documents are made available to the public by online reading or download. Danish rights holders have known about docplayer.dk for several years, as it has been possible to find copyrighted literary works on the platform without the consent of the rightholders. In 2016, the Association of Danish Journalists wrote on their membership magazine Journalisten that several journalists had found their articles and other material on docplayer.dk without their consent. Article from the Journalist of 22 June 2016 is presented as Annex 3. During the same period, member publishers in the association Danske Forlag also found a large amount of their works on docplayer.dk. The Rights Alliance was involved by the above-mentioned rights associations, both of which are members of the Rights Alliance. Our investigations in 2017 ended with a police review of the registrant of docplayer.dk in 2018, noting that our members’ protected works were systematically violated on the platform. In 2019, the StateAttorney’s Officehalted a special economic and international crime (SØIK) investigation into the case. This was done on the grounds that it was found unreportional to pursue the identification of a liability subject in the light of the expected punishment, as well as the fact that investigative steps in Russia against a Russian registrant were considered to have extremely long-term and resource-intensive prospects. The Rights Alliance then contacted DK-Hostmaster to clarify whether the registration of docplayer.dk met the verification requirements for .dk domains. In February 2020, DK-Hostmaster announced that the verification requirements had been met for docplayer.dk. The Rights Alliance then launched an in-depth investigation into docplayer.dk with the aim of assessing our ability to address the systematic violations of the works of our members. Our study has uncovered a service that systematically closes on the creative efforts of Danish authors under the guise of being a user-generated platform. The Rights Alliance shall submit as An Annex a report containing the results of our study of docplayer.dk. Annexes based on a main report “Technical report on Docplayer.dk” (pages 1 to 9) with four sub-reports, each describing a defined area: “Report on the implementation of the programme” (pages 1 to 9). examples of Docplayer.dk violations” (pages 10-14), “Docplayer.dk and obituary reports on Docplayer.dk” (pages 22-25), “Report on the coincidence of profile names on docplayer.dk and obituaries on afdoed.dk” (pages 26-76) and “Scraping report by Docplayer.dk” (pages 77 to 89). The report documents that the works of the Members of the Rights Alliance are stored and distributed to users from docplayer.dk’s own servers, and that the works are presented together with ads on docplayer.dk. See Annexes 22 to 25. The report also shows that docplayer.dk have been visited more than a million times in 2019. The Rights Alliance uses internet site visit data from the analytics company SimilarWeb. Data are given in Annexes 17 to 21. Vouchers are provided with a description of data from SimilarWeb. The report probable that some of the names of users who allegedly uploaded documents to docplayer.dk in June 2020 have been taken from the internet site afdoede.dk, which has published all published obituaries since 2006. See Annex pages 26-75. This result has been validated by Andreas Baum, Assistant Professor of Statistics and Machine Learning Department of Applied Mathematics and Computer Science Technical University of Denmark (DTU). See Annex pages 75 to 76. The report also probifies that some of the documents available on docplayer.dk have been collected and uploaded automatically from other internet sites via pro forma users created for the purpose of Docplayer.dk. The Rights Alliance has come to this conclusion by examining and comparing 420 Docplayer.dk users who allegedly uploaded 420 documents relating to the Royal Danish Yaghtklub (KDY) association with a list of real members of KDY. 420 Docplayer.dk users are alleged to have uploaded the 420 documents about KDY to docplayer.dk, but the usernames alone are again names on KDY’s membership list. See Annex pages 77-89. Based on the results of the report, the Rights Alliance assesses that docplayer.dk is registered for the purpose of exploiting the works of Danish rights holders without consent in order to generate ad revenue for the person(s) responsible for the service. The person(s) responsible have chosen a business model in which they automatically harvest Danish-language documents from other internet sites, store the documents on their servers, and distribute them on docplayer.dk under the guise of pro forma users, which the person(s) responsible has equipped with names taken from the internet site afdoede.dk. The Rights Alliance considers that the person(s) have chosen this model, as on the surface it appears that docplayer.dk is a user-generated platform. The model of automatic harvesting of documents means that the level of violations on docplayer.dk goes far beyond the members of the Rights Alliance, and potentially includes all documents available on docplayer.dk. Given the popularity of docplayer.dk, the Rights Alliance assumes that the person(s) responsible have made a significant profit from this model. … In support of the Rights Alliance’s claims, it is argued in summary that the domain name docplayer.dk be used systematically in violation of the Copyright Act and contrary to good domain name practice, cf. Law on Internet Domains § 25(1). This systematic unlawful application is examined below. The Rights Alliance has a significant legal interest in the outcome of the case, as our members Danish Publishers and the Rights of the Danish Journalists’ Association are violated on docplayer.dk to a systematic extent. It is therefore for the Board of Appeal to decide whether to transfer the domain name principally docplayer.dk to the Rights Alliance or, in the alternative, to delete the registration of docplayer.dk, cf. The Law on Internet Domains § 28(4)(1). Copyright Act The administrator of docplayer.dk conducts an illegal public performance in the form of illegal transmissions to the public of works belonging to the Members of the Danish Association of Rights Alliances Danish Publishers and the Danish Journalists’ Association. As stated in the report presented as an annex to this complaint, the Rights Alliance has documented that our members’ works are available on docplayer.dk and the works are stored and distributed from docplayer.dk’s servers. In addition, it is the administrator of docplayer.dk who has checked what content is available on docplayer.dk by collecting content from other internet sites and uploading it on docplayer.dk from pro forma users equipped with usernames retrieved at least from published obituaries and, in some case, also from other sources. According to Section 2(3) of the Copyright Act, cf. paragraph 4(3),1, authors have the exclusive right under the Copyright Act to perform their works publicly, including by making available in such a way that the public has access to them at an individually chosen place and time. The members of the Rights Alliance listed in Annexes 10 to 14 are all authors of the literary works in question, cf. Section 1 of the Copyright Act. The works in question are or have been available in such a way that the public can have access to the works at an individually chosen place and time in docplayer.dk. The members of the Rights Alliance have not authorised this provision, which is why it is contrary to Section 2(3) of the Copyright Act, cf. paragraph 4(1). There is much to be said for the majority of the content on docplayer.dk violates rights, as docplayer.dk collect Danish-language content from many internet sites. It is therefore not only the Members of the Rights Alliance who are being violated in docplayer.dk. Good domain name practice The registrant of docplayer.dk has chosen to register a .dk domain for the clear purpose of generating ad revenue by using content produced by third parties without prior consent to the use used. The registrant has further tried to hide his illegal actions by pretending to be a user-generated platform. However, the reality is that the registrant has at least used names from published obituaries to create pro forma users who allegedly uploaded content to docplayer.dk. It is a well-known technique of the criminal world to use the identities of deceased persons for criminal acts. The registrant also collects content from many other Internet sites and uncritically publishes the content on the service. This led to a case in which private individuals’ tax returns were published on the platform on the Dutch docplayer.nl. See Annexes 90-109 for a review of the Dutch case. There is nothing to prevent something similar from already being or will happen in docplayer.dk. For these reasons, the registrant of docplayer.dk has broken good domain name practice, cf. Law on Internet Domains § 25(1).” As an annex, the complainant has provided a copy of the complainant’s report of 4 August 2020 entitled “Technical report on Docplayer.dk”. Annexes transcript from the Central Business Register concerning the complainant. Includes a copy of the June 22, 2016 article from The Journalist headlined “This is the Internet’s Worst Nightmare,” which contains a story about the website “docplayer.dk.” Annexes are copies of a letter prepared by the complainant of September 2020 entitled “Rights Alliance data collection via SimilarWeb”. The pleas raised by the parties can be summarised as follows:
The Committee’s comments:
As the respondent has not responded to the Secretariat’s inquiries in the case, it is decided on the basis of the complainant’s presentation of the case and the supporting documents submitted by the complainant, in accordance with Paragraph 11(3) of the Board’s Rules of Procedure. The complainant claims that the domain name “docplayer.dk” should be transferred principally to the complainant and, alternatively, that the registration of the domain name “docplayer.dk” be deleted. It follows from Section 28(4)(1) of the Danish Domain Actthat the Board of Appeal may decide to “delete the registration of or transfer of a domain name registered or used in violation of Section 25, rules laid down pursuant to this Act, conditions of business or conditions established pursuant to §or registered or used in violation of other legislation in general”. In support of its claims that The complainant has pointed out that docplayer.dk the website does www.docplayer.dk contain a service that systematically violates copyright law, closes to the creative efforts of Danish authors under the guise of being a user-generated platform, and that the domain name “docplayer.dk” is registered for the purpose of exploiting the works of Danish rights holders without consent in order to generate ad revenue for the person or persons responsible for the service. On the other hand, the complainant does not claim that the use of the domain name “docplayer.dk” by the respondent on this website is unlawful. The information provided by the Board of Appeal does not provide a basis for establishing that the term “docplayer” is associated with the complainant, nor does the Board of Appeal find any other basis for establishing that the respondent’s choice of the domain name “docplayer.dk” for this service is in itself unlawful in relation to the complainant. The complaint in this case is thus in fact a complaint about the content and activities of a specific website and not a complaint about the registration and use of the domain name “docplayer.dk” as such by the respondent. Since the Domain Act does not give the Board of Appeal the power to rule on such a complaint, the complainant must be referred to the ordinary courts. The Board shall then take the following decision:
decision:
The complainant, the Rights Alliance, cannot be upheld.”
Update February 6, 2021: ‘Russian court case Mediamusic vs Vladimir Nesterenko’
We received the the following e-mail:
“[..] Due to the fact that Nesterenko violated the intellectual rights belonging to the Mediamusic, LLC (Russia), we applied to the Moscow courts with some claims (case No. 02-4091/2020, case No. 02-1229/2021, case No. 3-0134/2021). As evidence, we also referred to your investigation.
During the court proceedings it was found out that the full name of the fraudster is Vladimir Stefanovich Nesterenko, he is indeed registered at the address: Russian Federation, 111395, Moscow, st. Snaiperskaya, 2, bldg. 1, apt. 31, as you revealed in your investigation, and he really is the administrator of the docplayer.ru domain name.
In courts, he operates together with Intellect law firm, LLC (TIN 7704792348).
Third parties (users) were not identified during the court proceedings.
It was also established by courts that Vladimir Nesterenko really used the works belonging to the plaintiff, Vladimir Nesterenko placed the DOWNLOAD button for downloading the literary works, Vladimir Nesterenko embedded commercial advertising inside and outside of literary works.
However, our claims were unlawfully denied in full. The courts say that he is not at fault, as he is allegedly an information intermediary. And your investigation by the courts was declared fabricated. [..]”
Update March 14, 2021: ‘Russian court case Mediamusic vs Vladimir Nesterenko’
We received the the following e-mail:
“Vladimir Stefanovich Nesterenko — individual taxpayer number 772074180700, birthday 04.11.1983, address: 111395 Moscow, st. Sniper, 2, bldg. 1, apt. 31.
We filed a lawsuit against Vladimir Stefanovich Nesterenko with a claim for compensation for using our intellectual property on his website. Journalistic Investigation of RTL News found that he is illegally enriching himself, having many cloned sites that illegally distribute someone else’s intellectual property.
For the court, he hired seven lawyers at once, there is a power of attorney in the case, according to which it can be concluded that in fact he lives in the elite village of Barvikha near Moscow. His lawyers said in court that the RTL News investigation meant nothing. At the same time, Vladimir Stefanovich Nesterenko himself did not deny that he receives income from advertising on his website docplayer.ru, but this income is very small, and the court must take him at his word. And the court believed it, did not require evidence.
Vladimir Stefanovich Nesterenko did not take timely measures to end the violation (the lawsuit was filed in May 2020, and he stopped the violation only in November 2020). In court, he did not present any evidence and said that the court should believe him, that he did not receive and did not see the claim until November 2020. The court believed.
Vladimir Stefanovich Nesterenko also said that the works were uploaded by some unknown third parties and as evidence he presented a list with non-existent names and fictitious email addresses and ip-addresses, printed by him in WORD format [..]. Nesterenko did not present any documentary evidence to the court. He said he was assuring the court. The court believed him unconditionally.
Interestingly, the Perovsky District Court of Moscow and the Moscow City Court in every possible way prevented the plaintiff from obtaining information on the court case, the proven facts of the RTL News investigation did not even want to consider, all the written evidence of the plaintiff was simply rejected. That is, the courts ruled on Nesterenko’s innocence in the complete absence of evidence.
We believe that one person cannot carry out such large-scale projects (considering the number of such sites found by RTL News). These are machinations on the part of those in power in Russia, this is a whole mafia that steals the country even in terms of intellectual property. The courts, naturally, are on guard for violators, such as Vladimir Stefanovich Nesterenko. So, there can be no question of any kind of justice in Russia.”
Sites that link to this story:
| 2017-09-29 | RTLnieuws.nl | ‘Russische whizzkid wordt rijk door jouw documentjes’ |
| 2017-09-29 | RTLz.nl | ‘Russische whizzkid wordt rijk door jouw documentjes’ |
| 2017-09-29 | Tweakers.net | ‘Scrapingsite van Rus met 4,3 miljoen bestanden schendt privacy’ |
| 2017-09-29 | Bright.nl | ‘Rus verdient aan site vol PDF’jes van Nederlanders’ |
| 2017-09-29 | IOTnieuws.nl | |
| 2017-09-30 | Welingelichte Kringen.nl | ‘Een Rus zet Nederlandse privédocumenten online en wordt er rijk mee’ |
| 2017-09-30 | Zaufanatrzeciastrona.pl | ‘Weekendowa Lektura 2017-09-30 – bierzcie i czytajcie’ |
| 2017-09-30 | Badcyber.com | ‘IT security weekend catch up September 30, 2017’ |
| 2017-10-09 | TweedeKamer.nl | ‘Kamervragen van Kees Verkoeven (D66) over DocPlayer’ |
| 2017-10-11 | OfficieleBekend makingen.nl | ‘Vragen van het lid Bruins Slot (CDA) aan de Minister van Binnenlandse Zaken en Koninkrijksrelaties’ |
| 2017-11-09 | Rijksoverheid.nl | ‘Antwoorden kamervragen over het bericht Russische whizzkid wordt rijk door jouw documentjes’ |
| 2017-11-10 | Tweakers.net | ‘Minister: geen actie tegen scrapingsite van Rus met 4,3 miljoen bestanden’ |
| 2017-11-10 | Nu.nl | ‘Minister pakt Russische site met privédocumenten van Nederlanders niet aan’ |
| 2017-11-14 | Weblog post from Dutch lawyer Ellen Timmers | ‘Russische IT-ondernemer wordt slapend rijk met datagraaien’ |
| 2017-11-15 | Weblog post from Dutch lawyer Arnoud Engelfried | ‘Minister pakt Russische site met privédocumenten van Nederlanders niet aan’ |
| 2018-05-05 | CivisMundi.nl | ‘Google doet niets tegen crimineel scraping-bedrijf DocPlayer’ |
Pingback: Russische whizzkid wordt rijk door jouw documentjes | STRBNDblog.nl
Pingback: IT Security Weekend Catch Up – September 30, 2017 – BadCyber